In the vast majority of companies that I’ve been in, software engineering & infrastructure best practises have often been left as something that needs to be updated later because building the product comes first. This is completely understandable as if you don’t have a product, you don’t have employment. This presents problems later when companies are beginning to scale rapidly and become popular. Not only does the company becomes a target for malicious actors, but security-related incidents can easily occur by leaving storage devices open accidentally. Once a malicious actor is in your system, you usually have pretty big problems unless you design your architectures with Zero Trust in mind.
What is a Zero Trust Architecture
Zero trust means many different things to many different people, but the concept has its origins in Network Security. A Zero Trust Architecture aims to remove any source of inherent trust from the network, treat it as hostile and instead gain confidence that you can trust a connection through techniques like authentication and encryption. Zero Trust Architectures form a part of a more well-rounded defense in depth strategy.
The path to a fully Zero Trust Architecture is a long one, which you may argue is never complete because infrastructure rarely becomes stagnant and are always evolving. It’s important to recognise that moving to this style of architecture can be time-consuming and you should do so with care and plenty of testing before removing any existing control infrastructure. The following principals are a combination of some of the recommendations from national security bodies, AWS best practises and best practises that I consider important. This is not intended to be an exhaustive list, but form part of your research or provide a basic understanding.
Zero Trust Architecture Principals
Here are the principals that we are going to cover:
- Authentication & Authorization Everywhere
- Limit the scope of permissions
- Encryption At-Rest & In-Transit
- Prefer Managed Services
- VPC Subnet Isolation & Endpoints
- Use Transit Gateway to connect VPCs
- Choose Standards Where Possible
- Store secrets securely
Authentication & Authorization Everywhere
As mentioned earlier, part of the zero-trust model is not to trust anything by removing inherent trust. Authentication ensures that the requester is who they say they are, whereas authorization gives the requester access to resources.
Authentication everywhere means that we ensure that users, services and devices are successfully authenticated before performing any actions. Once authenticated, the entry point for each action checks the authorization of the user to ensure that they have the relevant permissions to perform the action. Frameworks like Asp.NET Core make this easy through the use of code-based policies in the identity framework.
Cloud providers typically have a robust identity and access management (IAM) system in place which removes the need to store credentials in services. Instead, credentials are derived from the service context and are authenticated on each request. If possible, avoid storing the credentials of a service that you need to access and favour service roles that have permissions to access the resources, leveraging the cloud providers IAM infrastructure. You can see the AWS IAM Security Best Practises Here.
For users in your organization, one easy to add protection layer is to ensure multi-factor authentication (MFA) is enabled for the services that support it. Typically this is added to authentication systems to prevent malicious actions when a password is compromised. In addition, some cloud providers and services allow you to enforce MFA when deleting or changing resources, preventing damaging actions for an already authenticated user.
Limit the scope of permissions
One of the tendencies when building out services is to give a service full administration privileges, usually when troubleshooting or initial development. Unfortunately, it is common to see that these elevated permissions are left in-place when troubleshooting has completed and the service is running as normal. Instead, start with a minimum set of permissions and grant additional permissions as necessary - without going to full administration privileges from the start. Doing so is more secure than starting with permissions that are too lenient and then trying to tighten them later. This is also known as the principal of least privilege.
An example of this would be a reporting service. Typically, a reporting service does not have a requirement to write data to a database, only to extract and present to the user. In a zero-trust model, we would create a unique login for the reporting service and limit it’s access to only those database entries it requires. We would also ensure that the user is a read-only user so if the service is compromised then a malicious actor cannot insert or alter any of the data stored in the database.
AWS supports permissions boundaries for IAM entities (users or roles). A permissions boundary is an advanced feature for using a managed policy to set the maximum permissions that an identity-based policy can grant to an IAM entity. An entity’s permissions boundary allows it to perform only the actions that are allowed by both its identity-based policies and its permissions boundaries. Add IAM users into IAM Roles to make the management role-based rather than elevating individual users. With role-based permissions, you should limit the scope to only the permissions that are required for the role the users fulfil, exactly like we do with services. With multiple teams, the permissions should be limited to the infrastructure components that the team manages. For example, do not give access to all DynamoDB instances.
For organizations, you can investigate the use of a service control policy (SCP). Service control policies are a type of organization policy that you can use to manage permissions in your organization. SCP’s offer central control over the maximum available permissions for all accounts in your organization. SCP’s alone are not sufficient to granting permissions to the accounts in your organization. No permissions are granted by an SCP. An SCP defines a guardrail, or sets limits, on the actions that the account’s administrator can delegate to the IAM users and roles in the affected accounts.
Here is an example of a limited IAM policy: 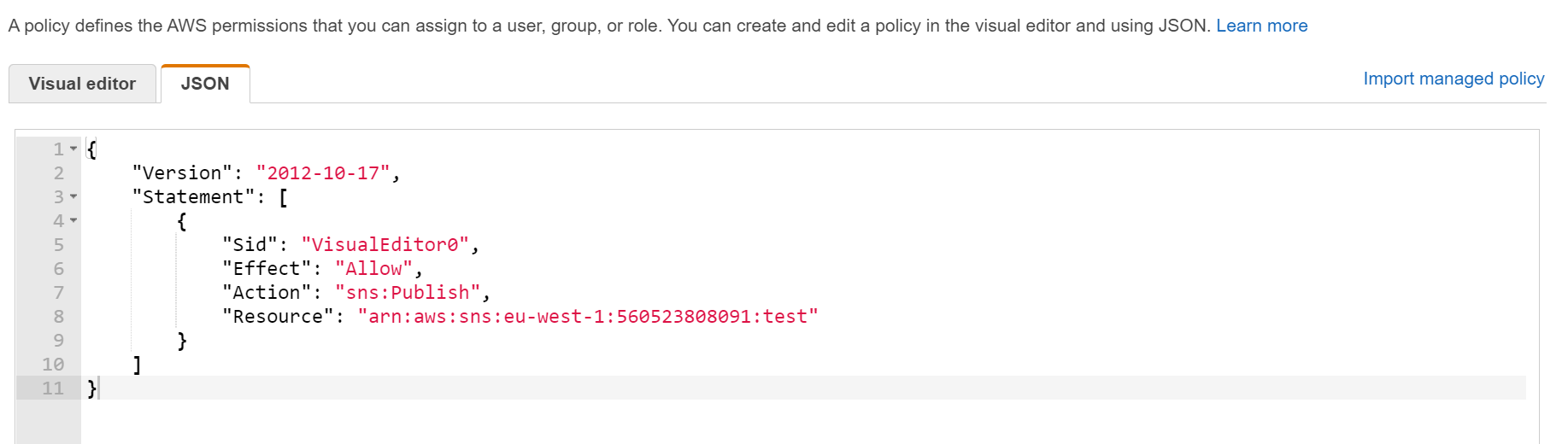
You can read more about AWS IAM Policy Boundaries here and Service Control Policies here.
Encryption At-Rest & In-Transit
Over the past couple of years, we’ve seen a massive movement towards securing websites with certificates and ensuring that all traffic is sent via HTTPS. Protocols like ACME and HSTS help ensure that implementation of HTTPS is easy, cheaper and consistent. Unfortunately, the security story usually ends there for most organizations unless there is a regulatory reason. We need to consider both Encryption At Rest and Encryption In-Transit.
Encryption In-Transit refers to the encryption that’s applied to data as it transits from one system to another. For the web, this is often seen as HTTPS but Encryption In-Transit includes any data that is sent over the network meaning that we need to take a look at all the protocols we use like web sockets, AMQP and SQL. It is often possible to use a TLS based connection to meet this part of the principal. Using TLS everywhere doesn’t guarantee the service is authenticated, just that the connection is secured and it hasn’t be changed inflight. You may consider implementing mutual TLS (or MTLS) for additional authentication requirements.
Encryption At Rest refers to the encryption that’s applied to data when it is persisted to disk. When building out infrastructure, engineers tend to only think about data storage areas like DynamoDB, S3 and SQL Server as places that they need to have encryption at rest. When looking at the architecture holistically, we need to consider a lot more which often requires digging into provider-specific documentation to find the answers. Here are a few examples from AWS, where data can be persisted on disk for the purposes of retries and reliability:
SQS
In-transit encryption is provided, but you must opt-in to at-rest encryption: 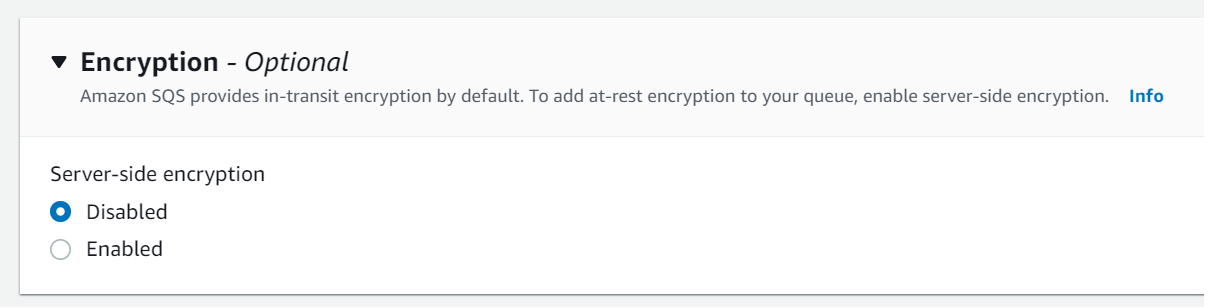
SNS
In-transit encryption is provided, but you must opt-in to at-rest encryption: 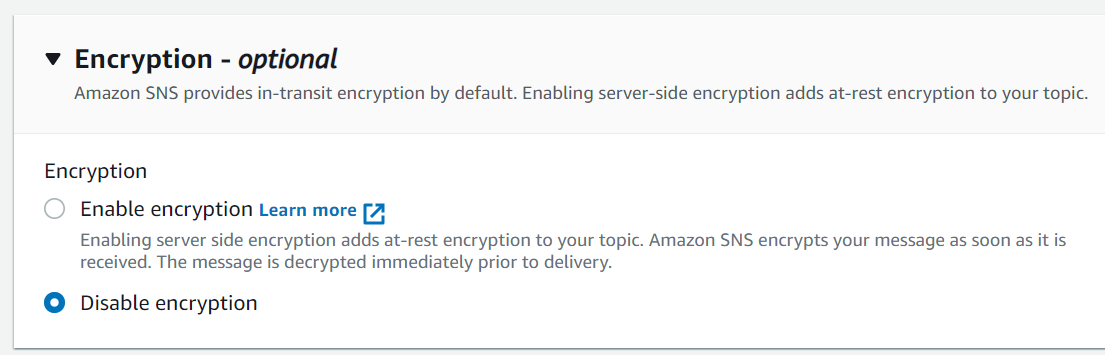
By performing end to end encryption both at rest and in-transit, we often meet any regulatory needs such as PCI and GDPR compliance. In the UK, the Information Commissioner’s Office can now issue fines of up to 4% of a company’s annual turnover, or 20 million (whichever is greater) for the worst data offences - so this is something that we should always be considering.
Prefer Managed Services
Another common pattern that I see is the use of custom-built services where a suitable managed service exists. A classic example of this is SQL database servers. Most cloud providers have managed service offerings which look after key parts of the platform like patching of the OS, replication and more. Moreover, they usually implement the best security practises, or at least offer them as a useable template. The chances are you’re like me and not an expert in configuring these systems, so it’s best to leave it to the professionals unless we have a legitimate case for managing it ourselves. Even then, we need to challenge all the aspects of the self-hosted use case to ensure that it fits we our desired security profile.
VPC Subnet Isolation & Endpoints
Most cloud providers allow you to isolate your compute resources into a separate area, called a Virtual Private Cloud (VPC). You can easily customize the network configuration of your VPC. You can assign a CIDR range and configure your subnets in accordance with your business requirements. There are four types of subnets that you should consider implementing:
- Public subnets: Anything that should be internet accessible, eg: NAT Gateways, Bastion hosts etc
- Private subnets: Accessible from the public subnets. Has access to database & intra subnets. Able to talk to the internet.
- Database subnets: Only accessible from private and intra subnets. Typically no internet access available to instances.
- Intra subnets: Services that access resources that live inside of the VPC and require no internet access. AWS resources will require a VPC Endpoint to work.
Even when inside of a VPC in AWS, it is a little known fact that your traffic to AWS services will traverse via the public internet. The solution to this is VPC Endpoints. A VPC Endpoint enables private connections between your VPC and supported AWS services and VPC Endpoint services powered by AWS PrivateLink. AWS PrivateLink is a technology that enables you to privately access services by using private IP addresses. Traffic between your VPC and the other service does not leave the Amazon network. A VPC Endpoint does not require an internet gateway, virtual private gateway, NAT device, VPN connection, or AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to communicate with resources in the service.
For serverless architectures, we may be utilizing Lambdas for the scaling capabilities it can provide. A Lambda may execute outside of a VPC entirely, as shown in the picture below. This means it would by-pass any protections that you have inside of your VPC. I would personally recommend that all functions are isolated into their own subnets inside of your VPC.
Use Transit Gateway to connect VPCs
In AWS, you can configure a transit gateway to route internal traffic between VPCs. AWS Transit Gateway can be configured with or without route propagation. It’s advised to explicitly set the associations between your VPCs so that you know what connects to what. This forms part of the know your network and services that the National Cyber Security Centre advises. An example of how to set this up using terraform can be found here.
A secondary advantage of using transit gateway is that it has a robust monitoring solution in-place. This is vital for a zero-trust architecture because you need to know and understand your network. You may also define a network access control list (NACL) as an optional layer of security.
Choose Standards Where Possible
Whenever possible, use standards-based technologies. This allows interoperability between devices and services. A good example of which is authentication and authorization, where common standards such as OpenID Connect, OAuth or SAML allow you to use a single directory service to authenticate to many services. Moreover, when you are (re)implementing something that already exists, you are likely missing the thousands of peer-reviews that typically happens for widely adopted standards. You are also not going to get any on-going support either from standards bodies or the surrounding communities. If there are tool chains in your organization, try to standardize on them. For example, if you have a toolchain for authentication, use the same toolchain everywhere and ensure that it is consistently configured through the use of packages (ie: NPM/NuGet packages).
Store secrets securely
Occasionally, we will have configuration settings that need to be kept secret, these will often change on a per-environment basis. A typical approach would be to use Octopus Deploy’s variables to keep these values secure and then deploy a new task definition with the variables set as environment variables on the task definitions. This represents a number of problems as the values are stored in plain text in the task definition and available on the container in plaintext. This means that a malicious actor could extract these values pretty easily from either the host or the running container depending on which has been compromised. A better approach would be to use AWS Secrets Manager or AWS Parameter Store to store the configuration settings and pull these directly from with your application code. Both AWS services can then be limited to a few select users to manage the configuration, such as engineering leads. With this approach, the configuration is no longer accessible without doing a direct memory dump from within the container.
When we come around to highly confidential information, we should be looking into the use of Nitro Enclaves. AWS Nitro Enclaves enables customers to create isolated compute environments to further protect and securely process highly sensitive data such as personally identifiable information (PII), healthcare, financial, and intellectual property data within their Amazon EC2 instances.
Enforcing Compliance In Zero Trust Architectures
Having a set of guiding principals is a good start towards a zero-trust architecture but the most important aspect of it is observation and compliance.
Observability
One of the most important aspects of zero-trust architectures is the use of monitoring. AWS, as mentioned above, has a number of great tools built into the products for the purposes of monitoring and alerting. Monitoring ideally is continuous, but it can also be periodic in nature. Alerting should be setup for the aspects of the systems that you are most concerned about. For example, you may have an alert for when a critical security group is modified. The remediation of the alert may be automatic, but you should be aware that the violation has occurred in the first place.
Compliance
There are two forms of compliance that we need to consider: pre-deployment / post-deployment.
Pre-deployment validation can be a little tricky depending on the toolchain that you use. If you use Terraform then you have a couple of choices: Terraform Enterprise and SpaceLift. Both allow for a form of codified policies which can prevent resources being created if they don’t match specific standards.
Post-deployment could easily be handled by tools like CloudCustodian. CloudCustodian allows you to define a series of policies that ensure your infrastructure follows a set of defined guidelines. Should a policy be violated, you have the choice on whether to act on the violation. For example, you may want to turn off an EC2 instance if the root storage device is not encrypted with a KMS key.
In reality, you will likely need a combination of pre & post-deployment compliance as there will always be scenarios where infrastructure is changed manually or a malicious actor could spin up new infrastructure.
Hopefully you now have a good understanding of what is meant by zero-trust architectures and you can leverage some of the tools and techniques mentioned to improve your security posture. I thoroughly recommend that you read through the National Cyber Security Centre - Zero Trust Architecture repository for more information on some of the topics listed in this post.